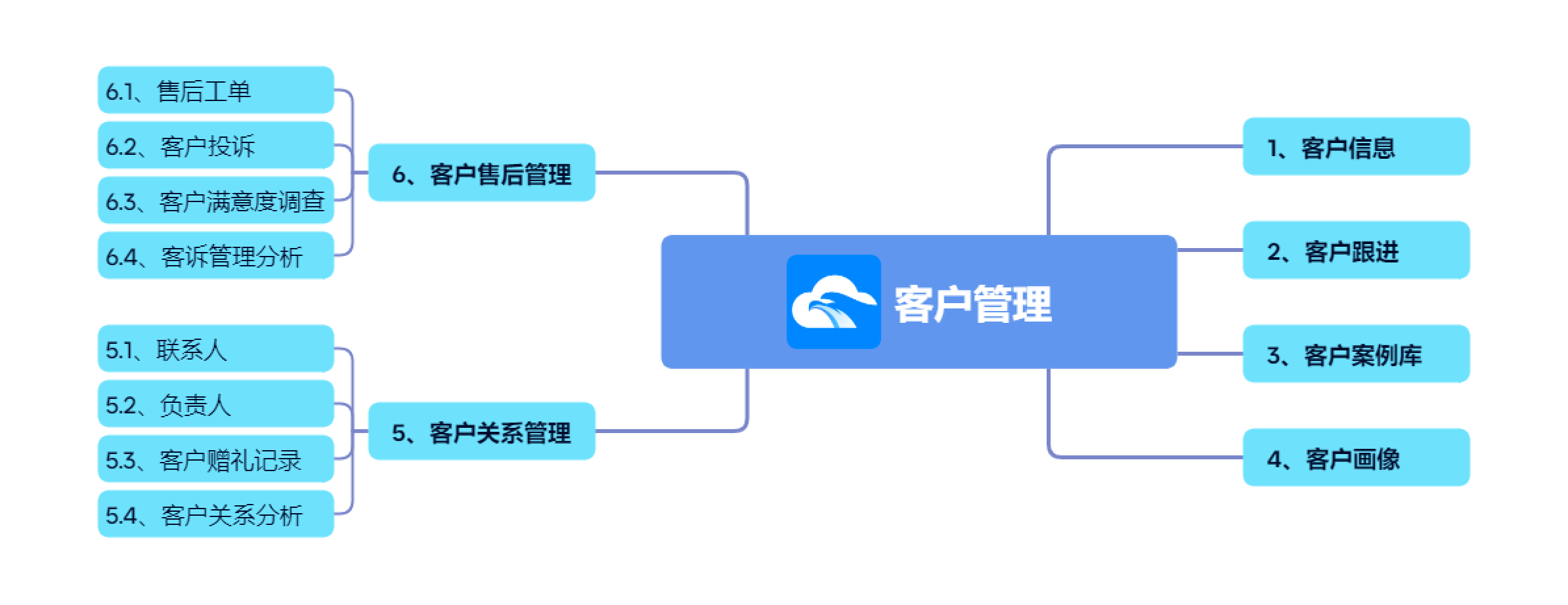
CRM客户管理系统,如何助力企业管理客户线索,提升转化率?
261
2023-11-13

【摘要】 本书摘自《Python网络爬虫 从入门到精通》一书中第4章,第3节,吕云翔、张扬和韩延刚等编著。
4.3 抓取动态内容
4.3.1 动态渲染页面
在上一节中可以看到,网页能够使用 JavaScript 加载数据,对应于这种模式,可以通过 分析数据接口来进行直接抓取,这种方式需要对网页的内容、格式和 JavaScript 代码有所研 究才能顺利完成。但大家还会碰到另外一些页面,这些页面同样使用 AJAX 技术,但是其页 面结构比较复杂,很多网页中的关键数据由 AJAX 获得,而页面元素本身也使用 JavaScript 来添加或修改,甚至于自己感兴趣的内容在原始页面中并不出现,而是需要进行一定的用户 交互(比如不断下拉滚动条)才会显示。对于这种情况,为了方便, 一般就要考虑使用模拟 浏览器的方法来进行抓取,而不是通过“逆向工程”去分析 AJAX 接口。使用模拟浏览器的 方法,特点是普适性强、开发耗时短,但抓取耗时长(模拟浏览器的性能问题始终令人忧 虑)。使用分析 AJAX 的方法,则刚好与模拟浏览器相反,即普适性较差,甚至在同一个网 站、同一个类别中的不同网页上, AJAX 数据的具体访问信息都有差别,因此开发过程投入 的时间和精力成本是比较大的。对于上一节提到的携程问答抓取,也可以用模拟浏览器的方 法来做,但鉴于这个 AJAX 形式并不复杂,而且页面结构也相对简单(没有复杂的动画), 因此,使用AJAX 逆向分析会是比较明智的选择。如果碰到页面结构相对复杂或者 AJAX 数 据分析比较困难(比如数据经过加密)的情况,就需要考虑使用浏览器模拟的方式了。
需要注意的是, “AJAX 数据抓取”和“动态页面抓取”是两个很容易混淆的概念,正 如 “AJAX 页面”和“动态页面”让人摸不着头脑一样。可以这样说,动态页面 (Dynamic HTML, 有时简称为 DHTML) 是指利用 JavaScript 在客户端改变页面元素的一类页面,而 AJAX 页面是指利用 JavaScript 请求了网页中数据内容的页面。这两者很难分开,因为很少 会见到只利用 JavaScript 请求数据或者只改变页面内容的网页,因此,将 “AJAX 数据抓 取”和“动态页面抓取”分开谈其实也是不太妥当的,这里分开两个概念只是为了从抓取的 角度审视网页,实际上这两类网页并没有本质上的不同。
4.3.2 使用 Selenium
在 Python 模拟浏览器进行数据抓取方面,Selenium (见图4- 15)必须被提及的。 Selenium (本意为化学元素“硒”)是浏览器自动化工具,在设计之初是为了进行浏览器的 功能测试。Selenium 的作用,直观地说,就是操纵浏览器进行一些类似于普通用户行为的操 作,比如访问某个地址、判断网页状态、单击网页中的某个元素(按钮)等。
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们 18664393530@aliyun.com 处理,核实后本网站将在24小时内删除侵权内容。




 ×
×