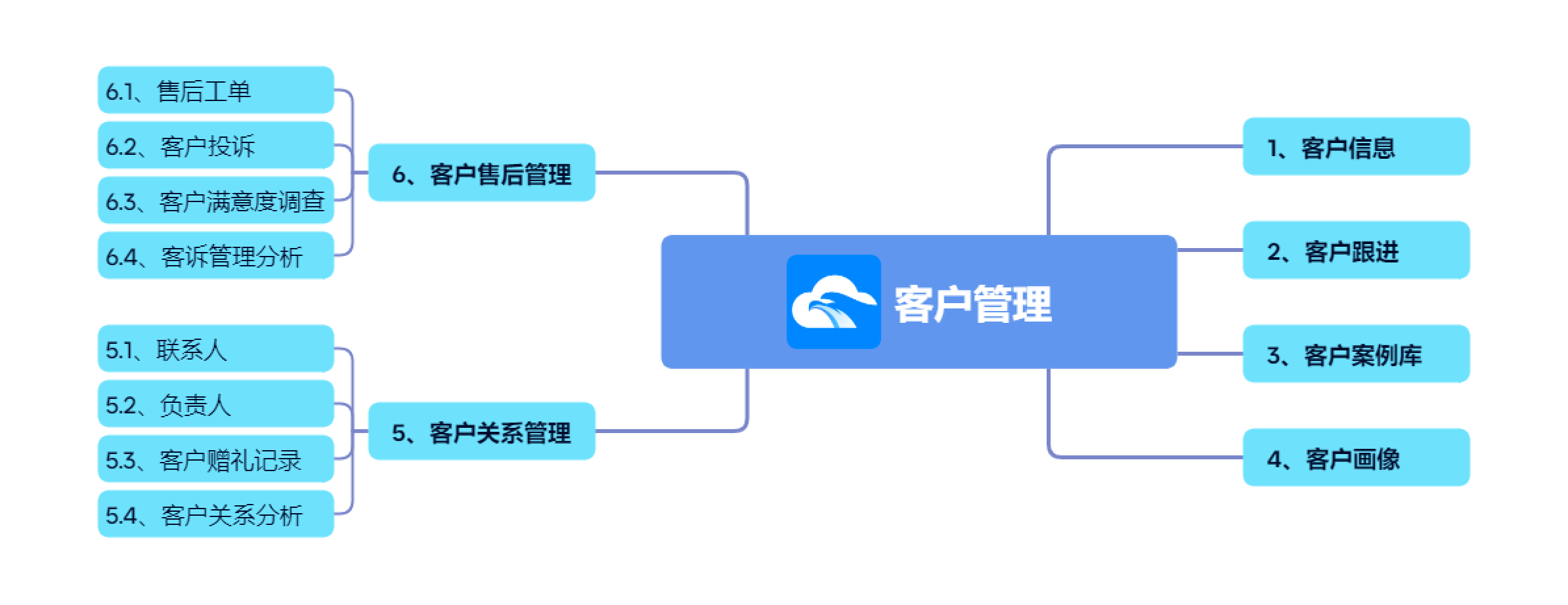
CRM客户管理系统,如何助力企业管理客户线索,提升转化率?
278
2023-11-13

【摘要】 本书摘自《Python网络爬虫 从入门到精通》一书中第2章,第2节,吕云翔、张扬和韩延刚等编著。
2.2.2 正则表达式的简单使用
正则表达式的具体应用当然不仅仅是在一个句子中找单词这么简单,还可以用它寻找 ping信息中的时间结果:
ping_ss ='Reply from 220.181.57.216:bytes=32 time=3ms TTL=47'
res =re.search(r'(time=)(\d+\w+)+(.)+TTL',ping_ss)
print(res.group(2))
输出为:3ms.
在爬虫编写时,也可以用正则表达式来解析网页。比如现在要获得百度的 title 信息,先 来观察一下网页源代码。下面是百度首页的部分源代码:

如果想要获得这些图片(的链接),大家首先会想到的方法可能就是使用 findAll(“img”) 去抓取。但是网页中的 “img” 却不仅仅包括这里需要的关于纽约市历史和情况的照片,
还有网站中通用的一些图片——logo 、 标签等,这些也会被抓取到。设想一下,编写一个 通过URL 下载图片的函数,执行之后却发现本地文件夹多了很多自己不想要的与纽约市没 有任何关系的图片——这种情况是必须避免的。为了有针对性地抓取图片,可以配合正则 表达式:
import re,requests
from bs4 import BeautifulSoup
r=requests.get('https://en.wikipedia.org/wiki/New_York_City')
bs =BeautifulSoup(r.content)
imgs =bs.findAll('img',{'srcset':re.compile(r'([\s\S]+)(upload.wikimedia.org/ wikipedia/commons/thumb/)([\d\w])+/([\s\S])+\.jpg')})
for img in imgs:
print(re.search(r'([\s\S]+)(1.5x)([\s\S]+)','http:'+img['srcset']).group(1))
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们 18664393530@aliyun.com 处理,核实后本网站将在24小时内删除侵权内容。




 ×
×