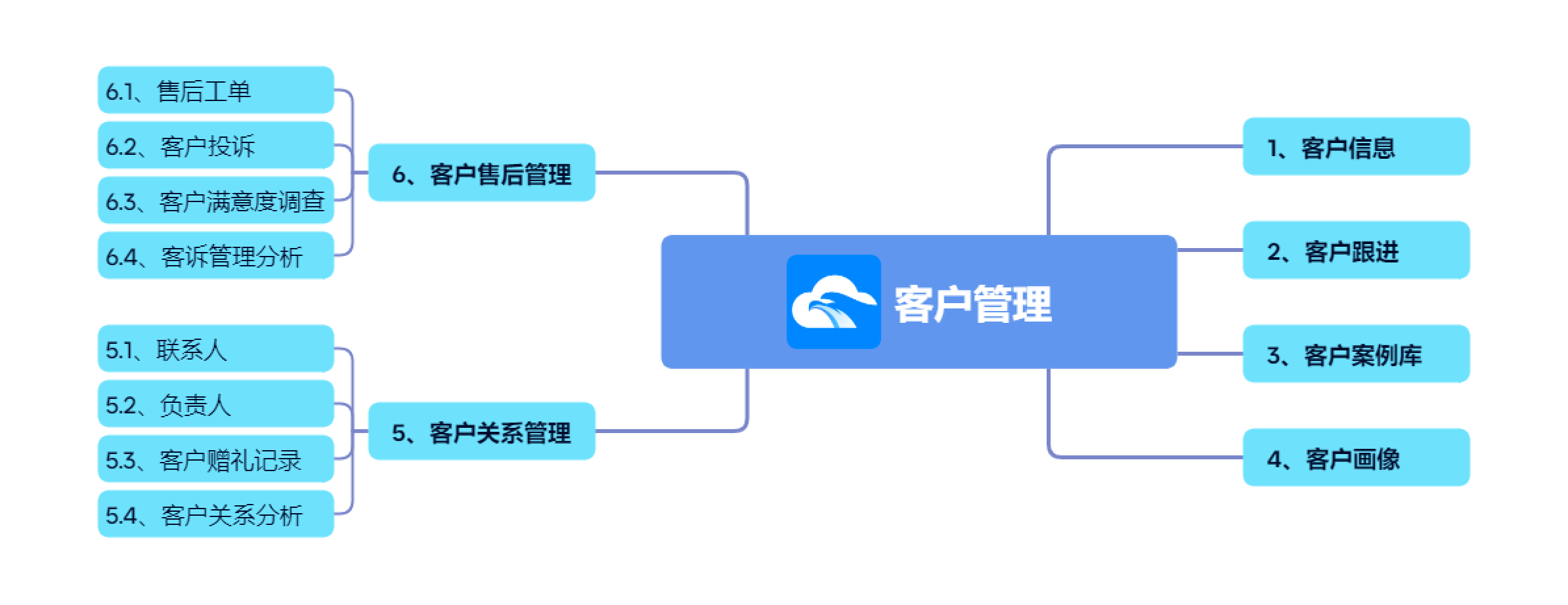
CRM客户管理系统,如何助力企业管理客户线索,提升转化率?
281
2023-11-13

【摘要】 本书摘自《Python网络爬虫 从入门到精通》一书中第9章,第2节,吕云翔、张扬和韩延刚等编著。
9.2.3 使用代理
大部分网站会根据 IP 来识别访问,因此,如果来自同一个 IP 的访问过多(如何判定 “过多”也是个问题, 一般是指在一段较短的时间内对同一个或同一组页面的访问次数较 大),那么网站可能就会据此限制或屏蔽访问。对付这种机制的手段就是使用代理 IP 。代理 IP 可以通过各种IP 平台乃至IP 池服务来获得,这方面的资源网络上非常多, 一些开发者也 维护着可以公开免费试用的代理IP 服务(见图9-10),安装这些服务后即可使用其提供代理 IP 的 API 接口,从而省去自己寻找并解析代理地址的麻烦。【提示】 代理 IP 应该叫“代理 IP 服务器”,其目标就是代理用户去获取网络上的信息,类 似于中转站的作用。代理服务器是介于客户端(浏览器等)和服务器之间的另一台“中介”服 务器,代理会访问目标网站,而用户需要通过代理来获取最终所需要的网络信息。
使用这样的更换不同代理 IP 的程序,就会让网站误以为收到了不同的请求,从而达到 “刷访问量”的效果,但其背后的技术原理是与躲避反爬虫机制有关的,也就是说,通过伪 装不同IP 的方式让网站方无法“记住”和“识别”这些程序,从而避免被封禁。
9.2.4 访问频率
对于避免“反爬虫”而言,其实最简单有效的手段就是直接降低对目标网站的访问量和 访问频次。某种意义上说,没有不喜欢被访问的网站,只有不喜欢被不必要的大量访问打扰 的网站。有一些网站可能会阻止用户过快地访问页面或提交数据(如表单数据),因此,如 果以一个比普通用户快很多的速度(“速度”一般指频率)访问网站,尤其是访问一些特定 的页面,也有可能被反爬虫机制认为是异常活动。从这个最根本的“不打扰”的原则出发,最有效的“反反爬虫”方法是降低访问频率,比如在代码中加入 time.sleep(2)这种暂停几秒 的语句。这虽然是一种非常笨拙的方法,但如果目标是实现一个不被网站发现是非人类的爬 虫,这有可能是最有效的。
另外一种策略是,在保持高访问频次和大访问量的同时尽量模拟人类的访问规律,减 少机械性的迭代式抓取,这可以通过设置随机抓取间隔时间等方式来实现。机械性的间隔 时间(比如每次访问都间隔0.5s) 很容易被判定为爬虫,但具有一定随机性的间隔时间 (如本次间隔0.2s, 下一次间隔1.6s) 却能够起到一定的作用。另外,结合禁用 Cookie 等 方式则可以避免网站“认出”爬虫的访问,服务器将无法通过 Cookie 信息判断爬虫是否已 经访问过页面。
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们 18664393530@aliyun.com 处理,核实后本网站将在24小时内删除侵权内容。




 ×
×