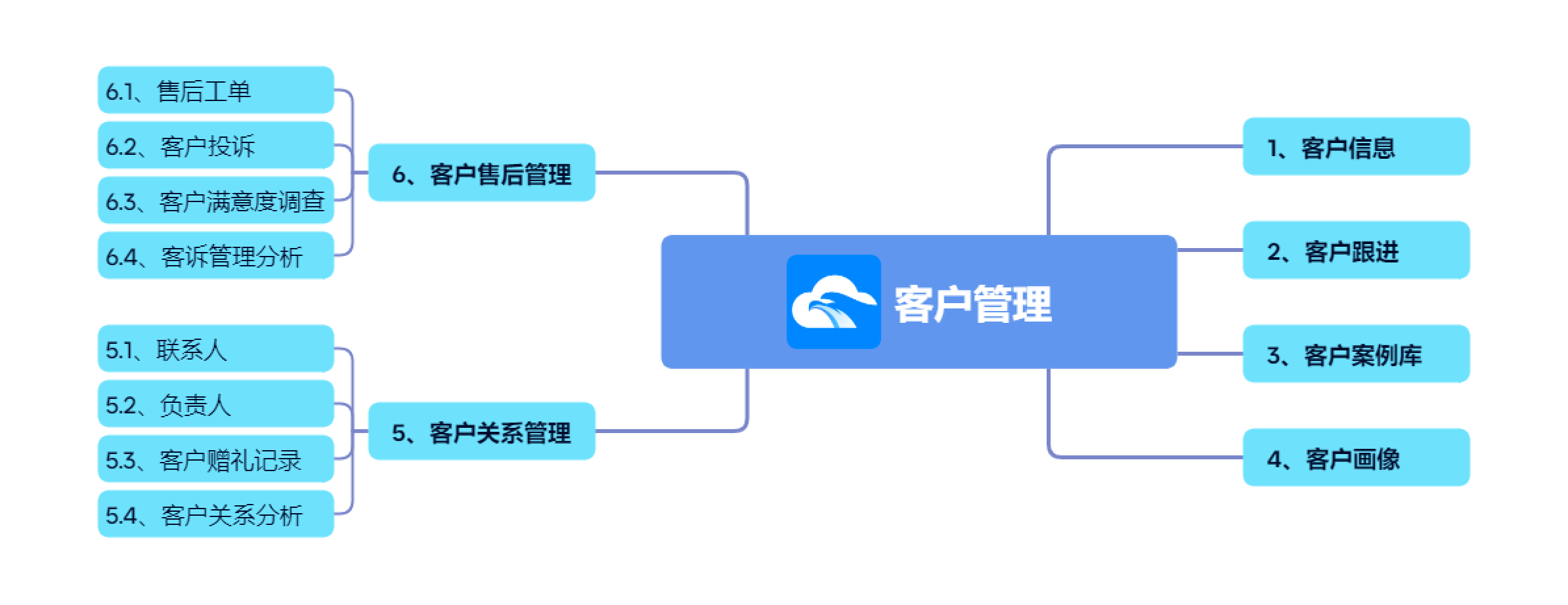
CRM客户管理系统,如何助力企业管理客户线索,提升转化率?
293
2023-11-13

【摘要】 本书摘自《Python网络爬虫 从入门到精通》一书中第6章,第1节,吕云翔、张扬和韩延刚等编著。
6.1 Python 与文本分析
6.1.1 什么是文本分析
文本分析,也就是通过计算机对文本数据进行分析。其实这不是一个很新的话题,但是 近年来随着 Python 在数据分析和自然语言处理领域的广泛应用,使用 Python 进行文本分析 也变得十分热门。
【提示】 结构化数据一般是指能够存储在数据库里,可以用二维逻辑表结构来表达的数 据。与之相反,不适合通过数据库二维逻辑表来表现的数据就称为非结构化数据,包括所有 格式的办公文档、文本、图片、XML 、HTML 、 各类报表、图像和音频/视频信息等。这种 数据的特征在于,其数据是多种信息的混合,通常无法直接知道其内部结构,只有经过识别 及一定的存储分析后才能体现其价值。
由于文本数据是非结构化数据(或者半结构化数据),所以一般都需要对其进行某种预 处理,这时可能遇到的问题包括:①数据量问题,这是任何数据预处理过程中都可能碰到的 一个问题,由于现在人们在网络上进行文字信息交流十分广泛,文本数据规模往往也非常 大;②在文本挖掘时,往往会将文本(词语等)转换为文本向量,但一般在数据处理后,向 量都会面临维度过高和过于稀疏的问题,如果希望进行进一步的文本挖掘,可能需要一些特 定的降维处理;③文本数据的特殊性,由于人类语言的复杂性,计算机目前对文本数据在逻 辑和情感上的分析能力还很有限。近年来机器学习技术火热发展,但在语言处理方面的能力尚不如图像视觉方面的成就。
一般来说,文本分析(有时候也称为文本挖掘)的主要内容包括以下几个方面。
●语言处理。虽然一些文本数据分析会涉及较高级的统计方法,但是部分分析还是会 更多地涉及自然语言处理过程,如分词、词性标注、句法分析等。
●模式识别。文本中可能会出现像电话号码、邮箱地址这样的有统一表示方式的实 体,通过这些特殊的表示方式或者其他模式来识别这些实体的过程就是模式识别。
●文本聚类。即运用无监督机器学习手段归类文本,适用于海量文本数据的分析,在 发现文本话题、筛选异常文本资料方面应用广泛。
●文本分类。即在给定分类体系下,根据文本特征构建有监督机器学习模型,达到识 别文本类型或内容主旨的目的。
丰富的 Python 第三方库提供了一些文本分析的实用工具。这里要说的是,文本分析与 字符串处理并不是一个含义,字符串处理更多的是指对一个字符串在形式上进行一些变换和 更改,而文本分析则更多地强调对文本内容进行语义、逻辑上的分析和处理。在整个分析的 过程中需要使用一些基本的概念和方法,在各种实现文本挖掘的工具中, 一般都会有所体 现,它们包括以下几项。
●分词。是指将由连续字符组成的句子或段落按照一定规则划分成独立词语的过程。 在英文中,由于单词之间是以空格作为自然分界符的,因此可以直接使用空格 (Space) 符作为分词标记,而中文句子内部一般没有分界符,所以中文分词比英 文要更为复杂。
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们 18664393530@aliyun.com 处理,核实后本网站将在24小时内删除侵权内容。




 ×
×