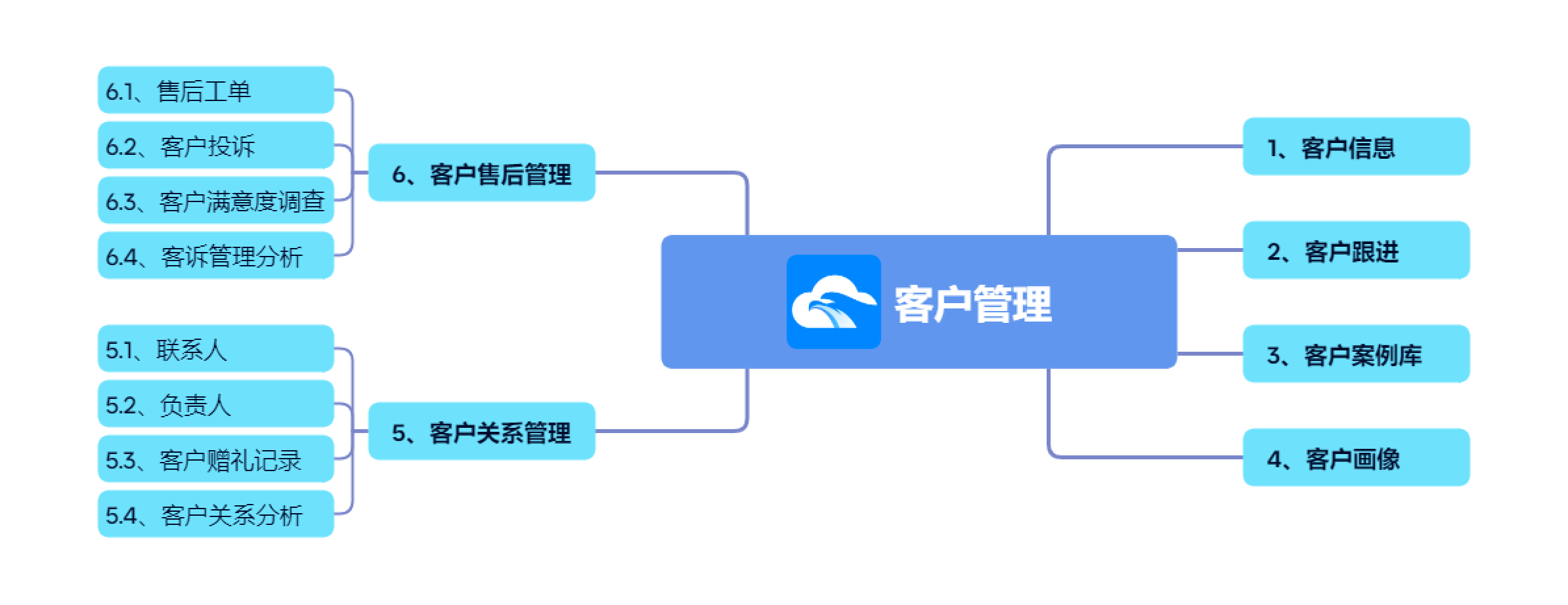
CRM客户管理系统,如何助力企业管理客户线索,提升转化率?
300
2023-11-13

【摘要】 本书摘自《Python网络爬虫 从入门到精通》一书中第6章,第1节,吕云翔、张扬和韩延刚等编著。
6.1.4 文本分类与聚类
分类和聚类是数据挖掘领域非常重要的概念,在文本数据分析的过程中,分类和聚类也 有举足轻重的意义。文本分类可以用于判断文本的类别,广泛用于垃圾邮件的过滤、网页分 类、推荐系统等,而文本聚类主要用于用户兴趣识别、文档自动归类等。
分类和聚类最核心的区别在于训练样本是否有类别标注。分类模型的构建基于有类别标 注的训练样本,属于有监督学习,即每个训练样本的数据对象已经有对应的类(标签)。通 过分类学习,可以构建出一个分类函数或分类模型,这也就是常说的分类器,分类器会把数 据项映射到已知的某一个类别中。数据挖掘中的分类方法一般都适用于文本分类,这方面常 用的方法有:决策树、神经网络、朴素贝叶斯、支持向量机 (SV M) 等。
与分类不同,聚类是一种无监督学习。换句话说,聚类任务预先并不知道类别(标 签),所以会根据信息相似度的衡量来进行信息处理。聚类的基本思想是使得属于同类别项 之间的“差距”尽可能小,同时使得不同类别项的“差距”尽可能大。常见的聚类算法包 括: K-means 算 法 、K- 中心点聚类算法、DBSCAN 等。如果需要通过 Python 实现文本聚类 和分类的任务,推荐使用 scikit-learn 库,这是一个非常强大的库,提供了包括朴素贝叶斯、 KNN、决策树、K-means 等在内的各种工具。
这里可以使用NLTK 做一个简单的分类任务。由于NLTK 中内置了一些统计学习函数, 所以操作并不复杂。比如,借助内置的 names 语料库,可以通过朴素贝叶斯分类来判断一个 输入的名字是男名还是女名,见例6-1。
【例6-1】 NLTK 使用朴素贝叶斯分类判断姓名对应的性别。
def gender_feature(name):
return ''isdt{_'flilθ],ame)//2]}
#提取姓名中的首字母、中位字母、末尾字母为特征
import nltk
import random
from nltk.corpus import names
#获取名字-性别的数据列表
male_names =[(name,'male')for name in names.words('male.txt')]
female_names =[(name,'female')for name in names.words('female.txt')] names_all =male_names +female_names
random.shuffle(names_all)
#生成特征集
feature_set =[(gender_feature(n),g)for(n,g)in names_all]
#拆分为训练集和测试集
train_set_size =int(len(feature_set)*0.7)
train_set =feature_set[:train_set_size]
test_set =feature_set[train_set_size:]
classifier =nltk.NaiveBayesClassifier.train(train_set)
for pr:\t.fo:lassify(gender_feature(name))))
程序中使用 “Amn” (女名)、“Sherlock” (男名)、“Cecilia” (女名)作为输入,输出为:
Ann: female
Sherlock: male
Cecilia: female
最后,使用 classifier.show_most_informative_features) 方法可以查看影响最大的一些特征 值,部分输出如下。
Most Informative Features
mid_letter ='w'
first_letter ='W'
first_letter ='U'
mid_letter ='f'
male :female =
male :female =
male :female =
male :female =
5.8 :1.0
4.7 :1.0
3.3 :1.0
2.9 :1.0
可见,通过简单的训练,已经获得了相对满意的预测结果。
最后要说明的是, NLTK 在文本分析和自然语言处理方面拥有很丰富的沉淀,语料也支 持用户定义和编辑。如上所述, NLTK 在配合一些统计学习方法(这里可以笼统地称之为 “机器学习”)处理文本时能获得非常好的效果,上面的姓名-性别分类就是一个小例子。统 计学习方法涉及的数学知识和 Python 工具较为复杂,已经超出了本书的讨论范围,在此就 不再赘述了。NLTK 还有很多其他功能,包括分块、实体识别等,都可以帮助人们获得更 多、更丰富的文本挖掘结果。
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们 18664393530@aliyun.com 处理,核实后本网站将在24小时内删除侵权内容。




 ×
×